At Creative Commons, we believe that addressing global challenges like the climate crisis requires opening the knowledge about those challenges. We are thrilled to announce the release of our “Recommendations for Better Sharing of Climate Data”— the culmination of a nine-month research initiative from our Open Climate Data project. These guidelines are a result of…
At CC we believe that to solve big problems, the knowledge and culture about those problems needs to be open and freely accessible. In line with our Open Climate Campaign, which focuses on opening up climate research, we recently launched the Open Climate Data project, to facilitate better sharing of climate data on a global…
by
Cable Green,
Monica GranadosOpen ClimateModern recut copy of The Great Wave off Kanagawa (神奈川沖波裏), from 36 Views of Mount Fuji, Color woodcut. Circa 1930 (original created 1829-1832). Public domain.
The Open Climate Campaign is pleased to see the recent wave of announcements requiring open access to knowledge that support our goal to make the open sharing of research outputs the norm in climate science. The Campaign recognizes that in order to generate solutions and mitigations to climate change, the knowledge (i.e. research papers, data,…
Mauricio says that “open access makes it easier for people to use what is a common good for all.” In this episode we dive into the work of a historian and librarian in Argentina. Mauricio discusses the value of cultural heritage preservation over generations and what role present day institutions play for the future. Open…
Charles shares that “open access [in cultural heritage] allows institutions to shine a light on lesser known works” that would otherwise go unnoticed. In this episode we get to learn about how a major French cultural institution creates value by making incredibly detailed data of collections available to the public online. Open Culture VOICES is…
Today, Creative Commons (CC) is excited to announce one million US dollars in new programmatic support from the Patrick J. McGovern Foundation (PJMF) to help open large climate datasets. The twelve-month grant will enable CC to conduct key climate data landscape analyses and expand our work, bringing people together to create policy and practices to…
Hi Creative Commoners! We are back with a brand new episode of CC’s Open Minds … from Creative Commons podcast. In this episode, we switch things up from our typical interview style and play back the recording of Creative Commons’ hybrid roundtable on the EU Data Act, which took place in Brussels on 14 June…
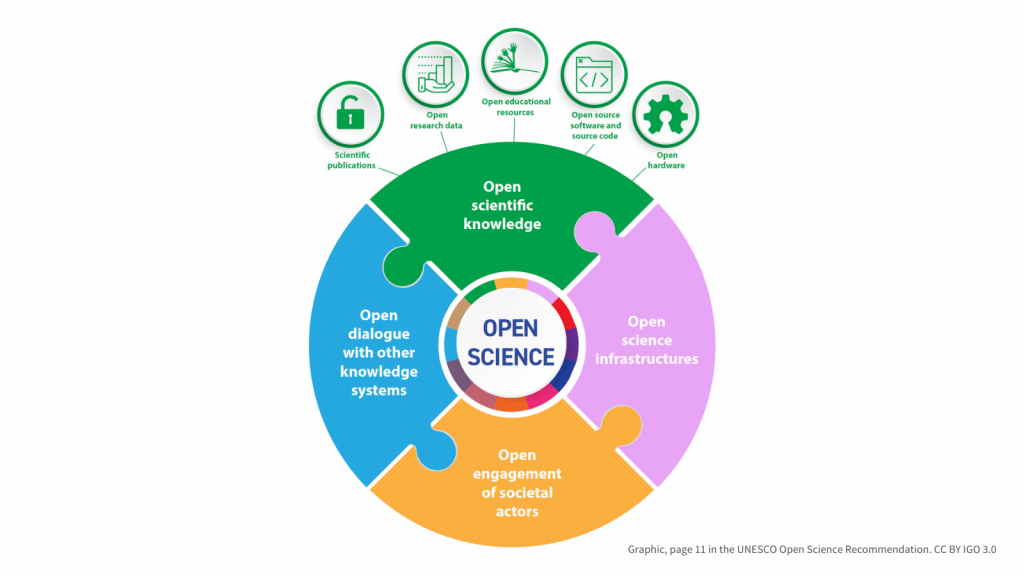
Graphic on page 11. UNESCO Recommendation on Open Science. CC BY IGO 3.0 Creative Commons (CC) applauds the unanimous ratification of the UNESCO Recommendation on Open Science at UNESCO’s 41st General Conference. This landmark document is a major step forward towards creating a world in which better sharing of science is open and inclusive by…
Happy Friday Creative Commoners! There are only 10 more days until this year’s virtual CC Global Summit, on September 20-24. In anticipation of the Summit, we’re doing something a little different in this episode. Pack your bags and prepare for a short (audio) tour around the world, join CC’s Ony Anukem as she speaks to…
We’re back with another episode of CC’s podcast, Open Minds … from Creative Commons! In this episode, I speak with Audrey Tang, who is the Digital Minister of Taiwan, as well as an influential free software programmer and hacker. Tang is a vocal proponent of openness and is working to manifest a vision for how…