



At the Grand Re-Opening of the Public Domain at the Internet Archive, I teased a new product vision for CC Search that gets more specific than our ultimate goal of providing access to all 1.4 billion CC licensed and public domain works on the web. I’m pleased to present that refined vision, which is focused on building a product that promotes not just discovery, but reuse of openly-licensed and public domain works. We want your feedback in making it a reality. What kinds of images do you most need and desire to reuse when creating your own works? Along that vein, what organizational collections would you like to see us prioritizing for inclusion? Where can we make the biggest difference for you and your fellow creators?
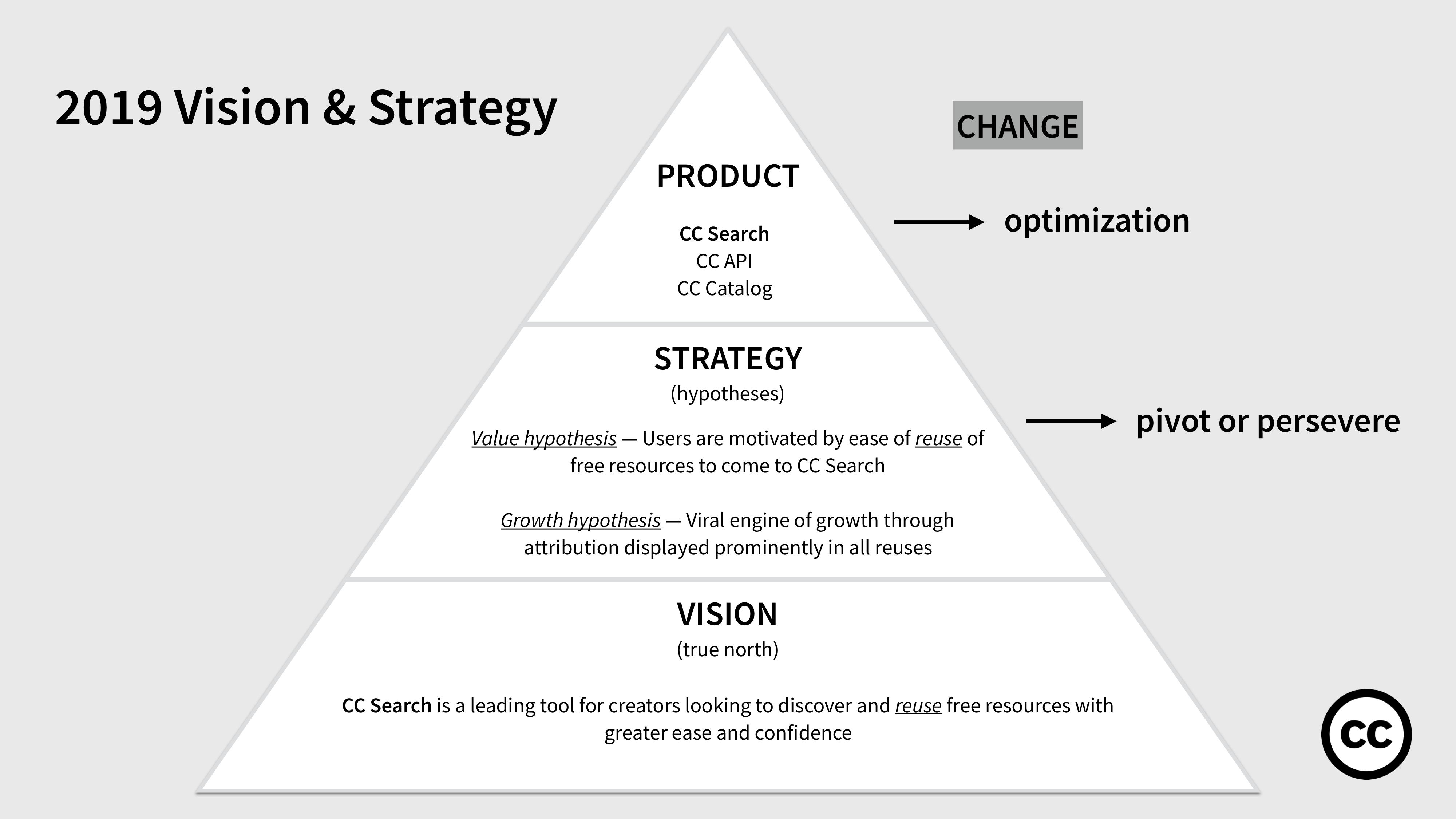
Vision
Our 2019 vision is:
“CC Search is a leading tool for creators looking to discover and reuse free resources with greater ease and confidence.”
The vision centers on reuse — CC will prioritize and build for users who seek to not only discover free resources in the commons, but who seek to reuse these resources with greater ease and confidence, and for whom in particular the rights status of these works may be important. This approach means that CC will shift from its “quantity first” approach (front door to 1.4 billion works) to prioritizing content that is more relevant and engaging to creators.
We made our assumptions based on a combination of user research, whatever quantitative data we could get our hands on (e.g. analytics on previous iterations of search), and pure conjecture (based on anecdotal evidence from our community), or what in the lean start-up world is called a leap of faith.
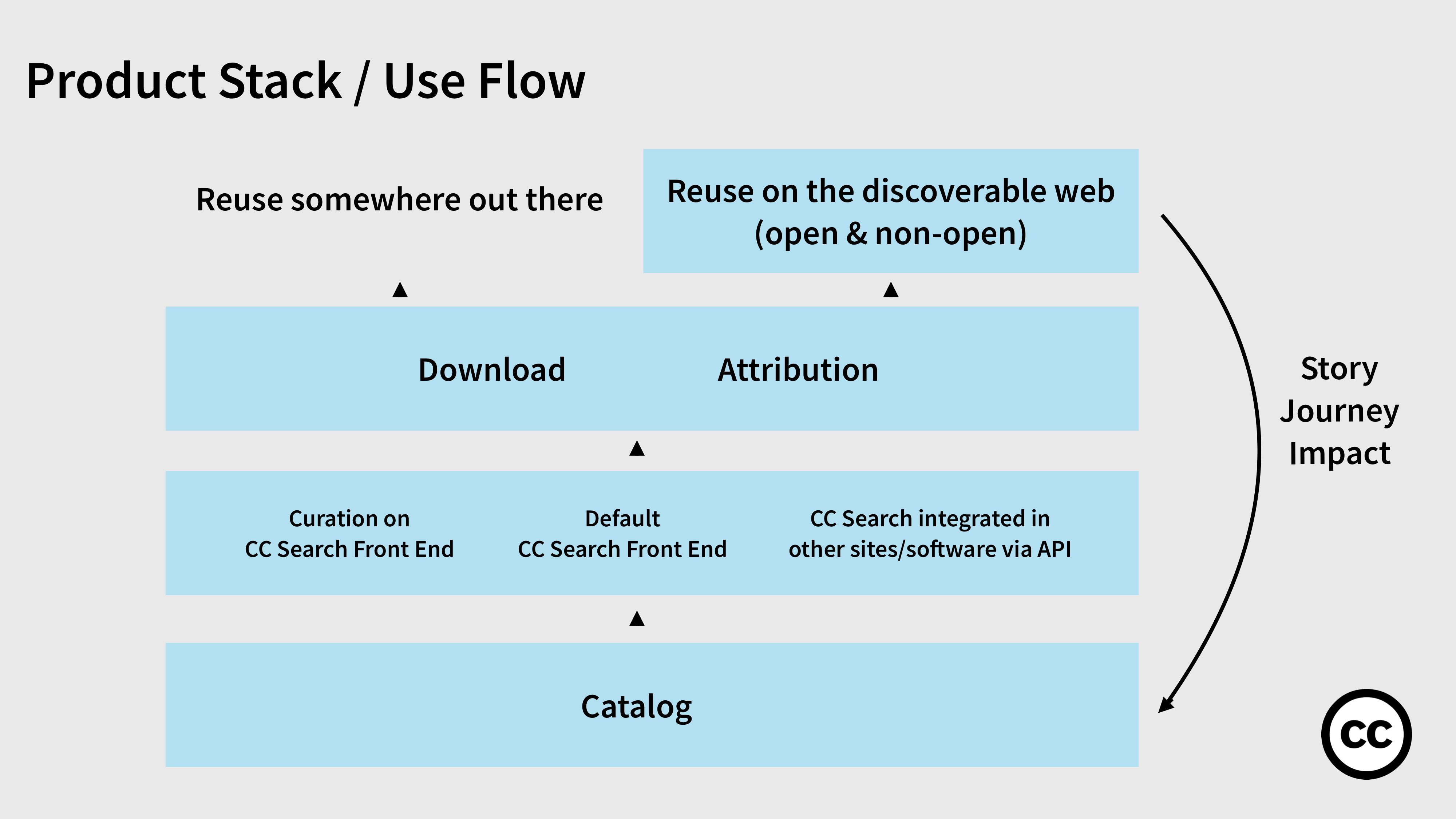
How we expect reuse to happen
The base catalog is the database of all CC works we are continuing to gather and grow. We envision users will be able to access this catalog in three ways:
- Through CC Search — the default front end you see now.
- Through some curation on CC Search — you could imagine different portals for different kinds of users, e.g. educators seeking open textbooks.
- Through CC Search being integrated directly into other sites and software via a CC API, e.g. CC Search in Google Docs.
Once the user accesses the work, the user takes the next step to reuse the work. They download it, which means they make a copy. The user who is also a creator takes a step further; they attribute the author of the work in their new creation, ideally through the automatic and easy ways we provide for them to do this. Both download and attribution are ways a user reuses the work in a way that implicates copyright and thereby the Creative Commons license. And both are potential ways we can learn how that work is used in the wild.
Through learning about how CC works are reused, we will be able to validate our hypotheses and know we are on the right track (or not). We will also be better able to tell the story or journey of the works’ impact, which speaks to a key insight from our user research:
“People like seeing how their work is used, where it goes, and who it touches, but have no easy way to find this out.”
This learning is the hard part of our work, and what we still need to figure out. How do we track and learn about reuse in a way that is effective, but also aligns with our values and respects user privacy?
User research & usability testing
In 2019, we will focus on images and texts, with a stretch goal of including audio files. Accordingly, we will focus any user research and usability testing on groups of people that reuse these works in a meaningful way, specifically, “Creators making new works using existing free content.” A few we will start with are:
- Creators making designs, imagery and art works (commercial or independent)
- Creators illustrating a text or text-based resource (blog, journalistic articles, educational/academic texts or presentations)
- Creators making a video
We’ll also being doing some separate user research to add open texts, which is a different bucket of people than the creators above, because we think (but don’t know) that most people seeking open texts are really seeking access, and not reuse, when it comes to CC Search. For example, we think that community college faculty looking for open textbooks are mainly seeking to access all open textbooks in one place.
As we talk to users, collect user feedback, and conduct usability testing, we may learn differently.
Roadmap
Based on this new 2019 vision and strategy, here are some of our key deliverables for the year.
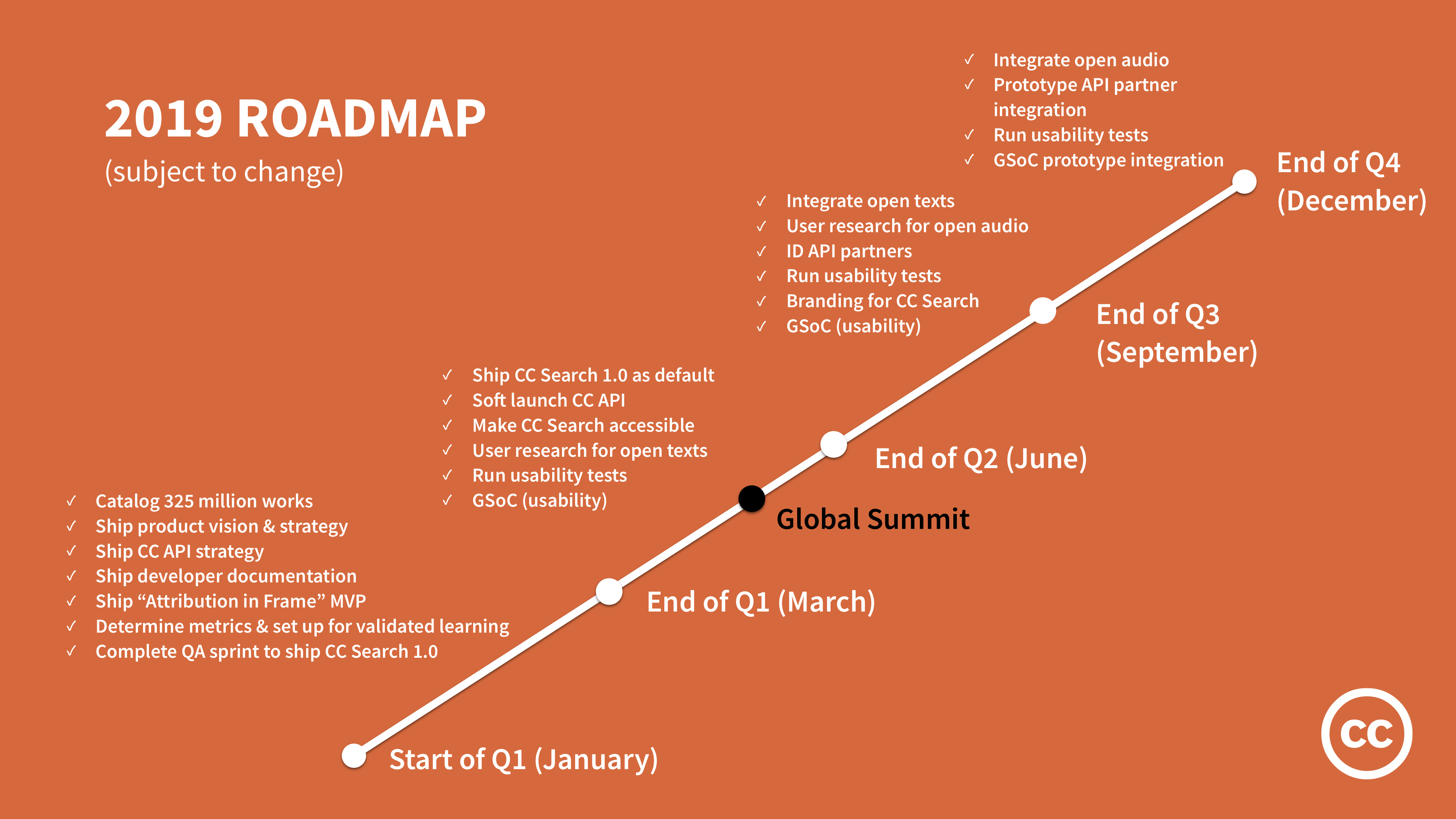
The complete roadmap is available here, which also includes a pipeline of ideas. The pipeline of ideas is the master list of ideas from the community that we will revisit at the end of each quarter to decide what makes it in the roadmap. The roadmap is an evolving document and we welcome your comments and feedback.
The Team

Follow the arrows from upper left: Kriti, Sophine, Alden, Breno, Sarah, Jane
The current CC Search team is led by CC’s Director of Engineering, Kriti Godey, and myself, CC’s Director of Product and Research. The other members are Sophine Clachar (Data Engineer), Alden Page (Back End Engineer), Breno Ferreira (Front End Engineer) and Sarah Pearson (Product Counsel).
Get involved
We are growing a vibrant community of open source developers and users willing to test and provide feedback on CC Search.
If you’re a current or potential user of CC Search, join the #cc-usability channel at the Creative Commons Slack (https://slack-signup.creativecommons.org) where we regularly engage the group for feedback on new features.
If you’re a developer, check out Creative Commons Open Source, a hub for the CC developer community and the #cc-developers channel at the Creative Commons Slack.
Posted 19 March 2019