This month marks the first anniversary of the Open Climate Campaign — a four-year project working to make the open sharing of research the norm in climate science. We celebrate the success of the campaign in this initial year and look forward to the upcoming year.
In early 2020, something unusual happened in the academic community. A normally guarded community accustomed to holding their data and research papers close, began to adopt much more open practices. Researchers came in droves to preprint servers to post versions of their research papers – that had not yet been peer reviewed – to make…
CC is thrilled to be partnering with the Wikimedia Foundation to make Wikimania 2023 a reality. The gathering takes place 16–19 August both in Singapore and online. Whether you can make it to Singapore or not, register now to attend, participate, and access recorded sessions. The CC and Wikimedian communities overlap in many ways and…
2023 is the year of the rabbit in the Chinese Lunar calendar, the year Voyager 2 is predicted to overtake Pioneer 10 as the second-farthest spacecraft from Earth, and the Year of Open Science. In an announcement by the White House Office of Science and Technology Policy (OSTP), 2023 was declared the Year of Open…
Launched in 2018, the Creative Commons Certificate program has trained and graduated 1255 people from 65 countries to date. We celebrate the incredible projects in open knowledge and culture led by the graduates of our program. CC Certificate alumni have used the Certificate course knowledge in a number of ways—read about how alumni have worked…
To make open sharing of research outputs the norm in climate science, Creative Commons, SPARC and EIFL are proud to launch a 4-year Open Climate Campaign with funding from Arcadia, which builds on planning funds from the Open Society Foundations. Climate change, and the resulting harm to our global biodiversity, is one of the world’s…
Mountain View, CA 30 Aug 2022: Creative Commons, SPARC and EIFL today announce a new 4-year, $4-million (USD) grant from Arcadia, to fund the Open Climate Campaign. This grant, which builds on $450,000 (USD) in planning funds from the Open Society Foundations, will fund a four-year campaign to accelerate progress towards solving the climate crisis…
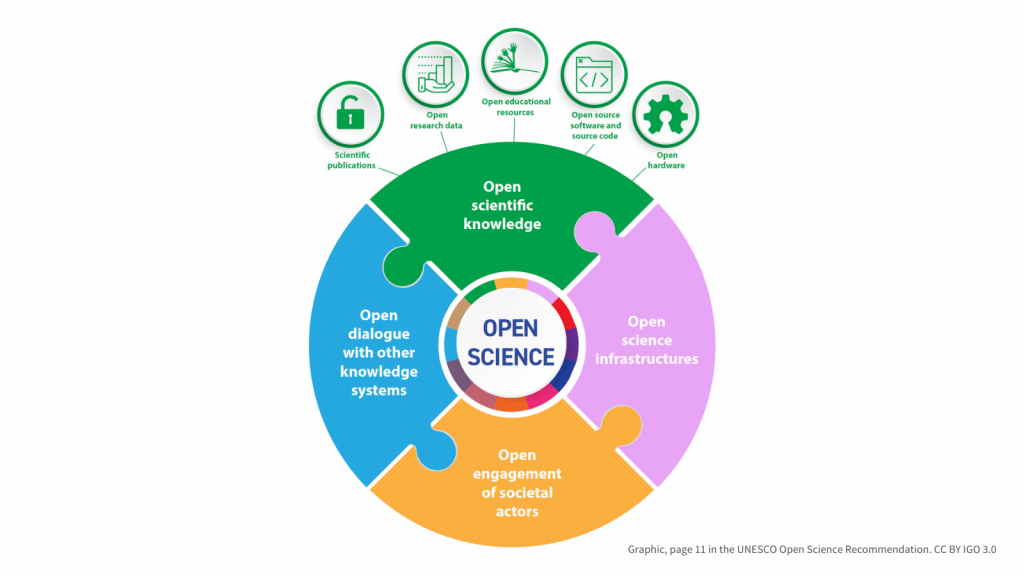
Graphic on page 11. UNESCO Recommendation on Open Science. CC BY IGO 3.0 Creative Commons (CC) applauds the unanimous ratification of the UNESCO Recommendation on Open Science at UNESCO’s 41st General Conference. This landmark document is a major step forward towards creating a world in which better sharing of science is open and inclusive by…
Open Science No Text. By: Greg Emmerich. CC BY-SA 3.0 As the United Nations Climate Change Conference, officially known as the 26th Conference of Parties, or COP26, continues in Glasgow, Scotland, I’m pleased to share some good news. The Open Society Foundations approved funding for Creative Commons, SPARC and EIFL to lead a global campaign…
The news yesterday from US trade Ambassador Katherine Tait that the Biden-Harris administration supports waiving IP protections for COVID vaccines is not just welcome, it is laying a stake in the ground for others to follow. The hesitancy of both the EU and UK to support the US places them on the wrong side of…
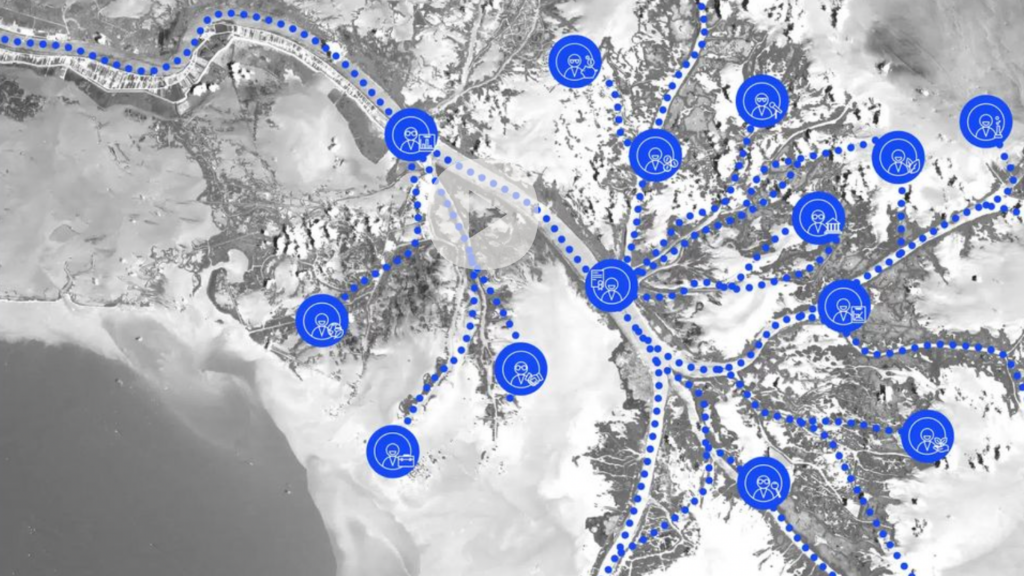 "River Banner" by Impact Media Lab for Creative Commons is licensed via CC BY 4.0.
"River Banner" by Impact Media Lab for Creative Commons is licensed via CC BY 4.0.
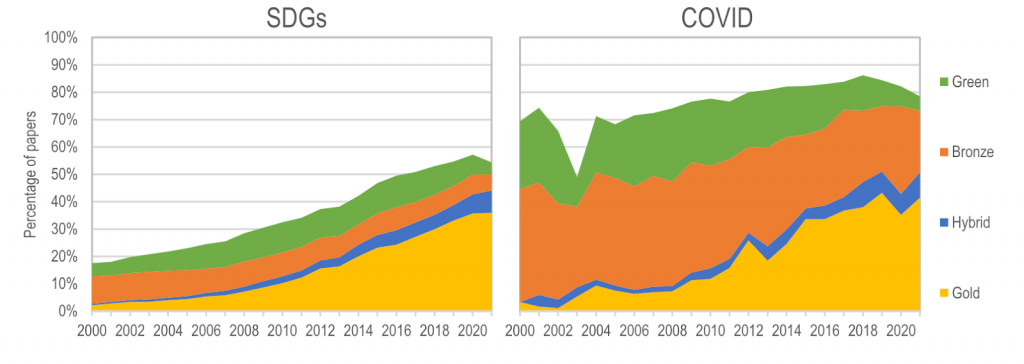





{kind=link}