In response to the COVID-19 pandemic, Creative Commons published an article titled, “Now Is the Time for Open Access Policies—Here’s Why” in March 2020. We felt it imperative to underscore the importance of open access, specifically open science, in times of crisis. A lot has changed since March of last year and it’s important to…
In response to the COVID-19 pandemic, Creative Commons published an article titled, “Now Is the Time for Open Access Policies—Here’s Why” in March 2020. A lot has changed since then and it’s important to assess the progress made and take a hard look at the dangers ahead. In this panel, we’ll examine the fields of…
Dear Mr. President-elect, First, I’d like to offer my sincere congratulations to you and to Vice President-elect Kamala Harris. This has been such a difficult year for so many around the world, and in this time of extreme polarization it is encouraging to hear you both talk about bringing people together to meet our common…
by
Victoria HeathOpen Access, Open ScienceAstronaut Edwin Aldrin walks on lunar surface near leg of Lunar Module. Credit: Neil Armstrong/NASA, (1969) in the public domain.
It’s July 20, 1969. Along with 600 million people, nine-year-old Chris Hadfield is glued to his television—watching intently as American astronaut Neil Armstrong glides down the ladder of the Lunar Module, and in one swift pounce, touches the dust of a familiar yet alien world. His words forever immortalized, “That’s one small step for man,…
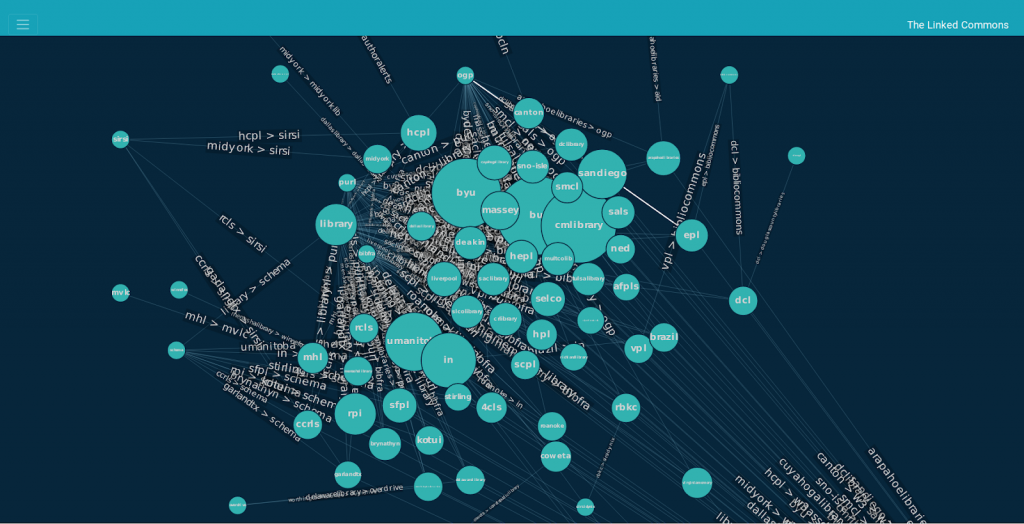
Open Data, TechnologyEducational community, including libraries and universities.
This is part of a series of posts introducing the projects built by open source contributors mentored by Creative Commons during Google Summer of Code (GSoC) 2019. Maria Belen Guaranda was one of those contributors and we are grateful for her work on this project. “By visualizing information, we turn it into a landscape that you can explore…
Today is the International Day for Universal Access to Information (IDUAI). You may be wondering why this day is necessary—particularly in 2019, when the average person is inundated with an estimated 34 gigabytes of information every day, from emails and text messages to Youtube videos and news programs. In fact, it’s easy to take information…
Last week the European Commission announced it has adopted CC BY 4.0 and CC0 to share published documents, including photos, videos, reports, peer-reviewed studies, and data. The Commission joins other public institutions around the world that use standard, legally interoperable tools like Creative Commons licenses and public domain tools to share a wide range of…
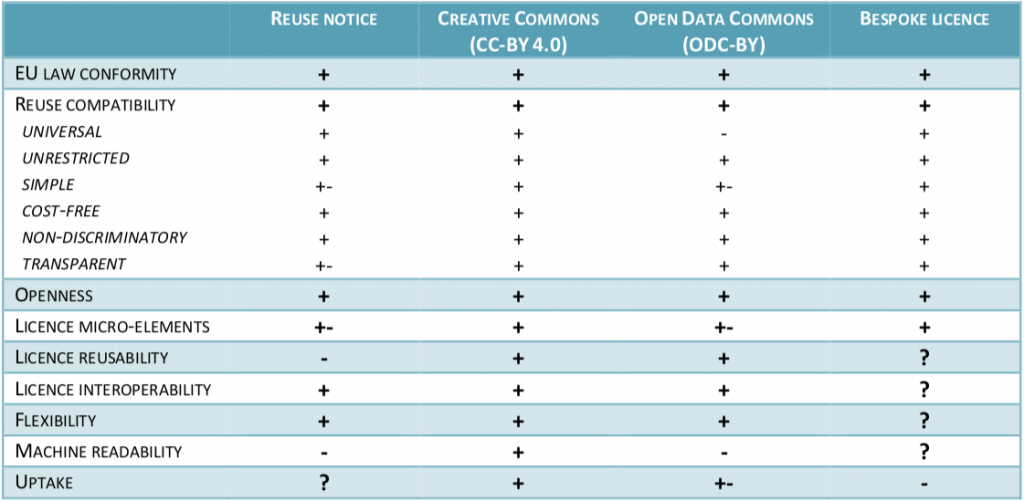
While the EU copyright reform teeters on the edge of turning into a complete disaster, last week the European Commission published a proposal for a revision of the Directive on the reuse of public sector information (PSI Directive), and a recommendation on access to and preservation of scientific information. Both of these documents are…
The Open, Public, Electronic, and Necessary Government Data Act (OPEN Government Data Act) has passed the U.S. House of Representatives. The bill’s text was included as Title II in the Foundations for Evidence-Based Policymaking Act (H.R. 4174). If ultimately enacted, the bill would require all government data to be made open by default: machine-readable and…
In the United States, there are two bills making their way through Congress that would require all government data to be made available in open and machine readable formats by default. The OPEN Government Data Act has been introduced in both the House of Representatives (H.R. 1770) and the Senate (S. 760). The bill would…