



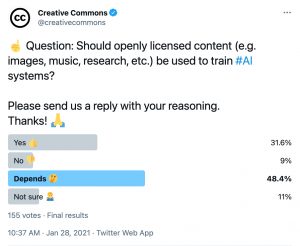
Developments in artificial intelligence (AI) raise several questions when it comes to the use of copyright material and Creative Commons-licensed content in particular.1 One of them is whether CC-licensed content (e.g. photographs, artworks, text, music, etc.) should be used as input to train AI. To get a sense of the various views on this question, we launched a Twitter poll where nearly half of respondents said, “it depends.” We agree and here’s why: while we generally support broad access to content to train AI, we also aim to increase our understanding of the ethical concerns that may constitute barriers to open sharing by creators.
 CC supports broad access to content in the public interest
CC supports broad access to content in the public interest
CC is dedicated to facilitating greater openness for the common good. We believe that the use of openly accessible content can lead to greater innovation, collaboration, and creativity. We also believe that the limitations within copyright law, which generally privilege the reuse of the facts and ideas embodied in creative works, contribute to a rich and generative public domain. CC thus supports, in principle, broad access and use of copyright works, including openly licensed content, to train AI in the public interest. Such access can, for instance, help reduce bias, enhance inclusion, promote important activities such as education and research, and foster beneficial innovation in the development of AI.
Does the training of AI implicate copyright?
Whether one has to comply with the copyright regime (and hence with the CC license terms) depends on whether the type of AI training activity is an exercise of a right reserved to the rightsholder.
There is no consensus on whether the use of copyright works as input to train an AI system is an exercise of an exclusive right.
There remains significant legal uncertainty about whether copyright applies to AI training, which means it may not always be clear whether a CC license applies. In other words, there is no consensus on whether the use of copyright works as inputs to train an AI system is an exercise of an exclusive right (e.g., reproduction, adaptation, etc.). The situation is likely to vary across jurisdictions, as countries progressively regulate the copyright-AI nexus. In the US, the use of works to train AI is likely considered fair use. In the EU, Article 3 of the Directive on Copyright in the Digital Single Market (DSM) provides an exception for non-commercial text-and-data mining (TDM, a form of AI) by research and cultural heritage institutions, while Article 4 offers an exception regime for commercial TDM, from which rightsholders may opt-out.

“How I Learned to Judge” by John Sloan Photography, licensed CC BY-NC-SA.
At CC, we believe that, as a matter of copyright law, the use of works to train AI should be considered non-infringing by default, assuming that access to the copyright works was lawful at the point of input. For example, TDM in the context of research or education should be allowed under an exception to copyright, following the adage that “the right to read is the right to mine.” As one commentator stated in our abovementioned Twitter poll: “Copyright should not be used as an instrument to stop data mining and AI research.” Regarding the use of CC-licensed content, a short refresher about how the licenses operate is in order.
CC licenses refresher
Our licenses do not restrict reuse to any particular types of reuse or technologies, so long as the attribution (BY), share-alike (SA), no-derivatives (ND) and non-commercial (NC) terms are respected. Therefore, strictly from a copyright perspective, no special or explicit permission is required from the licensor to use CC-licensed content to train AI applications to the extent that copyright permission is required at all.2 In addition, our licenses do not override limitations and exceptions, such as fair use. If a use is not one that requires permission under copyright or sui generis database rights (e.g. text and data mining allowed under an exception), one may conduct the AI training activity without regard to the CC license.
It’s also important to recall that our licenses operate within the copyright system. Privacy, personality, publicity and other types of rights or ethical considerations are not covered by the licenses.3 We do our best to ensure that those releasing their creations under our licenses understand the scope of the copyright rights that are managed under our licenses. For example, while a CC license may offer users permission to reuse a photo, it would not offer the permission users would need to make use of the personal likenesses of other people in the photo, which may be governed by image or personality rights.
Uncertainty around AI can raise additional barriers to sharing
Beyond the framework of freedoms that the licenses provide, there are concerns on the part of creators that their CC-licensed content can be used for problematic purposes, such as AI designed for facial recognition.
In 2019, we learned that researchers at companies like IBM were training their facial recognition AI programs by feeding their algorithms with CC-licensed photos from publicly available collections (e.g. one million photos on Flickr). IBM had not asked permission from the people photographed or the photographers. Some Flickr users were dismayed to learn that IBM had used their CC-licensed photos to train the AI, all the more so as it was done for commercial advantage. They had questions about the ethics and privacy implications of such a dataset being used for algorithmic training.4

The incident magnified the tension between the value of open data vs. legitimate concerns about ethical, moral and responsible use of openly licensed content. The United Nations Secretary-General António Guterres acknowledged that “advances in artificial intelligence-related technologies, such as facial recognition software and digital identification, must not be used to erode human rights, deepen inequality or exacerbate existing discrimination.”5 As with any fundamental ideal, the “openness” of data is not an absolute end in itself and must be balanced with equally valid considerations to ensure sharing ultimately benefits the public.
Our thoughts moving forward: an inclusive approach to support better sharing
Beyond copyright issues, AI is likely to affect the sharing of creative content and the open community in general. The legal uncertainty caused by ethical concerns around AI, the lack of transparency of AI algorithms, and the patterns of privatization and enclosure of AI outputs, all together constitute yet another obstacle to better sharing. Indeed, for many creators, these concerns are a reason not to share.
As one actor in a vibrant community of open advocates defending the interests of the millions of people who use CC licenses, we want to engage in rich conversations on AI’s multiple facets to promote better sharing in the public interest.
That’s why to promote the use of CC-licensed content to train AI, we need a community-led, coordinated and inclusive approach to consider not only the copyright system in which CC licenses operate, but also issues of accountability, responsibility, sustainability, cultural rights, human rights, personality rights, privacy rights, data protection, and ethics. As one actor in a vibrant community of open advocates defending the interests of the millions of people who use CC licenses, we want to engage in rich conversations on AI’s multiple facets to promote better sharing in the public interest.
To that end, the CC Copyright Platform of the Creative Commons Global Network will examine, throughout the year, the intersection of AI and open content. Through discussions and collective action, we look forward to exploring options in licensing and infrastructure, policy,6 norm building,7 and awareness-raising.
Are you interested in joining the conversation with policy experts from all over the world? Become a member of the CC Copyright Platform by joining our CC Policy Mailing List.
Notes
1. Our previous blog posts on AI include: Why We’re Advocating for a Cautious Approach to Copyright and Artificial Intelligence; Artificial Intelligence and Creativity: Why We’re Against Copyright Protection for AI-Generated Output and Artificial Intelligence and Creativity: Can Machines Write Like Jane Austen? See also our official submissions to the World Intellectual Property Organization (CC Submission to WIPO Consultation on AI and IP Policy (February 2020) and CC Statement at WIPO Conversation on IP and AI (2nd session) (July 2020)) and the European Commission (Creative Commons Submission to the European Commission Consultation on Artificial Intelligence (June 2020)).
2. For further information on our licenses and AI see our FAQ: https://creativecommons.org/faq/#artificial-intelligence-and-cc-licenses and https://creativecommons.org/faq/#can-i-conduct-textdata-mining-on-a-cc-licensed-database.
3. The licenses do, however, include a waiver from the licensor not to assert their own moral, publicity, privacy, and/or similar personality rights against reusers.
4. A tool called exposing.ai has since been developed to allow Flickr users to check if their CC-licensed photos were used to train facial recognition AI.
5. Guterres, A. (2020, Feb 24). The Highest Aspiration: A Call to Action for Human Rights. Geneva, Switzerland, UN Human Rights Council.
6. We want our policy work to focus on global, representative and inclusive advocacy efforts, notably in the context of the UNESCO Recommendation the ethics of artificial intelligence and the WIPO Conversation on Intellectual Property and Artificial Intelligence.
7. Lessons from the data collection practices of archives have been touted as useful guidance for developing codes of conduct and ethical guidelines in machine learning systems.