Unleashing a Community in Action: this year’s CC Global Summit Keynotes

This year, we’re taking an alternative, community-centered approach to keynotes for the Creative Commons Global Summit. In addition to two keynotes from four esteemed colleagues in open knowledge and the public domain, we’re bringing six community leaders to the stage for short talks on their work and experience. They were identified and selected by the Summit program committee.
The Community Keynotes join us from four continents and a variety of disciplines. From technology to journalism, these Creative Commons Global Network members are accomplished leaders in their fields participating in crucial work for a more open world. These keynotes will be: Majd al Shihabi of Lebanon, Sophie Bloemen of Amsterdam and Brussels, Kelsey Merkley of Canada, Natalia Mileszyk of Poland, Dr. Haggen So of Hong Kong, and Ọmọ Yoòbá of Nigeria. Their bios can be found below.
Majd Al-Shihabi is a systems design engineer based in Beirut, applying systems thinking to as many fields as he can reach. He works with a wide range of academic and cultural institutions and archives in the region to build openness into their information systems. He is interested in knowledge production outside of traditional institutions and knowledge dissemination to wider audiences. Majd is interested in studying how urban environments evolve and are shaped, which he is studying at the American University of Beirut. He is the inaugural recipient of the Bassel Khartabil Free Culture Fellowship, where he worked on two projects: PalestineOpenMaps.org, running mapathons to vectorize the content of historic maps of pre-Nakba Palestine; and MASRAD:platform, an open source tool for archiving oral history collections.
Sophie Bloemen is Director and co- founder of Commons Network, a think tank and civil society initiative based in Amsterdam & Brussels. She writes and speaks on social-ecological transitions, the commons and new narratives for Europe. She is engaged in a number of projects and political processes that explore new, creative institutions, collaborative models and bringing the commons perspective to policy. She has worked as an advocate and public interest consultant on policy issues like health, trade, innovation and R&D. @sbloemen
Kelsey Merkley is the founder of UnCommon Women, a project designed to advocate for leadership roles for women and celebrate those in leadership through the UnCommon Women Colouring Book. She is an advocate with almost a decade of experience working with local, national, and global organizations. Previously she was Creative Commons Public Lead in South Africa and later in Canada where launched numerous community-building projects. Kelsey now lives and works in Toronto, Ontario, Canada.
 Natalia Mileszyk is a lawyer and public policy expert dealing with digital rights, copyright reform and openness. She works for Centrum Cyfrowe, a leading Polish think-and-do-tank, where she analyses and comments on the social aspects of technology and a need for human-centered digital policy. She is also active in Communia Association for Public Domain and Creative Commons Poland. For the last three years, she has been actively involved in copyright reform advocacy at the European level. A graduate of the University of Warsaw and the Central European University in Budapest (LL.M.). You can find her on Twitter at @nmileszyk.
Natalia Mileszyk is a lawyer and public policy expert dealing with digital rights, copyright reform and openness. She works for Centrum Cyfrowe, a leading Polish think-and-do-tank, where she analyses and comments on the social aspects of technology and a need for human-centered digital policy. She is also active in Communia Association for Public Domain and Creative Commons Poland. For the last three years, she has been actively involved in copyright reform advocacy at the European level. A graduate of the University of Warsaw and the Central European University in Budapest (LL.M.). You can find her on Twitter at @nmileszyk.
 Dr. Haggen So is the president of the Hong Kong Creative Open Technology Association and the public lead of Creative Commons Hong Kong. He is a visiting lecturer of the Hong Kong Community College and previously taught in Hong Kong Baptist University as lecturer in the department of Computer Science. Dr. So also has experiences in commercial software development and developed software products for renowned companies such as Kodak.
Dr. Haggen So is the president of the Hong Kong Creative Open Technology Association and the public lead of Creative Commons Hong Kong. He is a visiting lecturer of the Hong Kong Community College and previously taught in Hong Kong Baptist University as lecturer in the department of Computer Science. Dr. So also has experiences in commercial software development and developed software products for renowned companies such as Kodak.
Ọmọ Yoòbá is a journalist with eleven years professional experience in the Nigerian broadcast media. He has dedicated eight years of his lifetime to the propagation of the Yorùbá ecological knowledge and cultural on the digital space. As an advocate of multilingualism and internet universality, Yoòbá had worked with stakeholders in the effort to bridge the digital divide, giving minority languages a voice on the Internet of Things, and marginalised society access to digital resources. In addition to teaching the Yorùbá language on tribalingua.com, Yoòbá is a volunteer translator and has worked with Localization Lab to localize digital security and Internet circumvention tools (EFF). He is the Lingua Manager of Global Voices in Yorùbá. In 2018, he collated more than a hundred oral literature of the Yorùbá which is in the archive of the Firebird Foundation for Anthropological Research in Phillips, Maine, United States.
In addition to these community keynotes, CC has invited two keynotes from four international leaders in free culture and open knowledge. Our first invited keynote is Adele Vrana and Siko Bouterse, co-directors of Whose Knowledge?, a global campaign working to create, collect and curate knowledge from and with marginalized communities, so that the internet we build and defend is ultimately an internet for all.
Our second invited keynote is James Boyle and Jennifer Jenkins of the Duke Center for the Study of the Public Domain, whose keynote will discuss music copyright, the Public Domain, and their work as advocates and lawyers to improve access to knowledge. Jenkins and Boyle recently spoke at our “Re-opening of the Public Domain” event in San Francisco. Watch the video to get a preview of their talk and read an interview with them on the CC blog.
The CC Global Summit will take place from May 9-11 in Lisbon. The program and registration is available at this link.
European Commission adopts CC BY and CC0 for sharing information
Last week the European Commission announced it has adopted CC BY 4.0 and CC0 to share published documents, including photos, videos, reports, peer-reviewed studies, and data. The Commission joins other public institutions around the world that use standard, legally interoperable tools like Creative Commons licenses and public domain tools to share a wide range of content they produce. The decision to use CC aims to increase the legal interoperability and ease of reuse of its own materials.
In addition to the use of CC BY, the Commission will also adopt the CC0 Public Domain Dedication to publish works directly in the global public domain, particularly for “raw data resulting from instrument readings, bibliographic data and other metadata.”
The European Commission joins governments such as New Zealand and the Netherlands in using CC licenses and CC0 to share digital resources it creates. Intergovernmental organisations, philanthropic charities, and funding policies already require CC licenses to be applied to the digital outputs of grant funds — to promote reuse of materials in the public good with minimal restrictions.
The decision to require reuse of Commission documents under CC BY and CC0 was determined alongside a study on available reuse implementing instruments and licensing considerations. Until now the Commission had been relying on “reuse notices” (a simple copyright notice with link to the reuse decision) that would accompany covered materials, but this practice produced “unnecessary administrative burdens for reusers and the Commission services alike.”
In 2014 the Commission released a recommendation on using Creative Commons licenses such as CC BY and CC0 Public Domain Dedication in the context of Member States sharing public sector information.
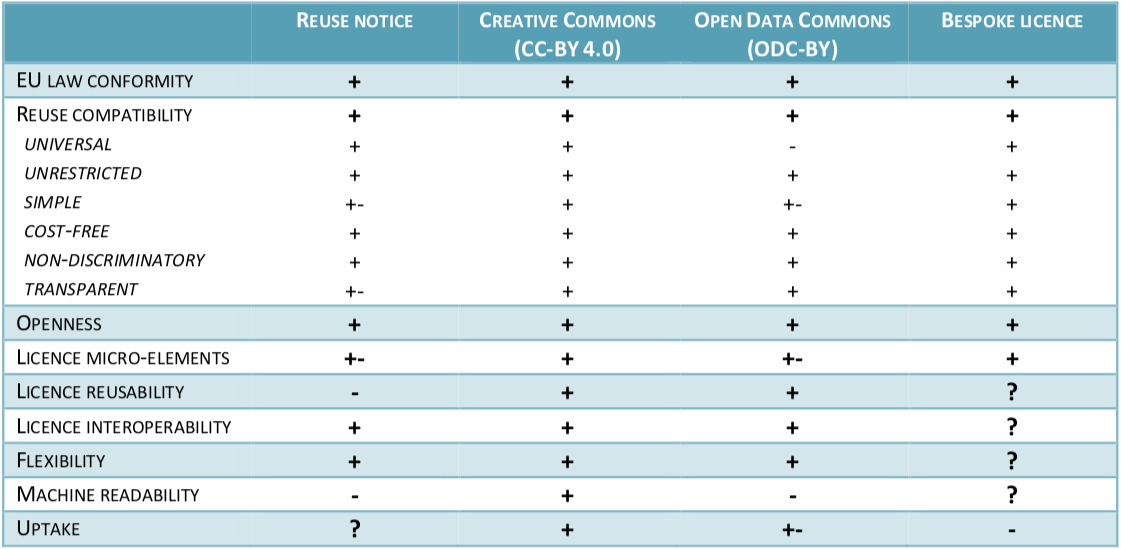
CC BY 4.0 receives top score in license evaluation
The study mentioned above evaluates various options for the Commission to consider for its own documents, including the “reuse notice”, CC licenses, the Open Data Commons licenses, and a potential bespoke Commission licence. Its authors determined that CC BY 4.0 is the license best aligned with the Commission’s principles for reuse. According to the report, CC BY 4.0 is:
- Universal: it is conceived to be applicable to all documents (at the choice of the licensor);
- Unrestricted: generally speaking, the only condition is attribution;
- Simple: there is no need for an application and it is user-friendly;
- Cost-free: the text of CC-BY does not require payment of fees;
- Non-discriminatory: terms of CC-BY are open to all potential actors in the market; [and]
- Transparent: the text of the licence is publicly available, accompanied by supporting documents, guidelines and other material in multiple languages.
The study notes that not all of the CC licenses and CC0 have been translated into the two dozen official EU languages; there are 10 remaining translations for CC 4.0 (some in progress) and 12 for CC0. We are working with the Commission and the CC EU network to complete the remaining translations.
Amid the disappointment with the vote in the Parliament on the copyright Directive last week, which leans toward a more restricted, less open web, it is heartening to see the Commission make progress on supporting reuse of the digital materials it creates and shares. We also look forward to upcoming vote this week on the recast of the Public Sector Information (PSI) Directive. This vote could increase the availability of PSI by bringing new types of publicly funded data into the scope of the directive, and provide improved guidance on open licensing, acceptable formats, and rules on charging.
The freedom to listen: Rute Correia on the power of community radio
 Academic, producer, and open culture enthusiast, Rute Correia is a Lisbon-based doctoral candidate who produces the White Market Podcast, which focuses on free culture and CC music. As both a student of radio and producer herself, she is deeply connected to the Netlabel and CC music communities, utilizing her significant talents to showcase free music, culture, and Creative Commons through community radio and open source.
Academic, producer, and open culture enthusiast, Rute Correia is a Lisbon-based doctoral candidate who produces the White Market Podcast, which focuses on free culture and CC music. As both a student of radio and producer herself, she is deeply connected to the Netlabel and CC music communities, utilizing her significant talents to showcase free music, culture, and Creative Commons through community radio and open source.
Rute will be joining us at the Creative Commons Global Summit in Lisbon from May 7-9 to talk about her exciting new project, the Open Music Network. Find out more about the Summit, and don’t forget to register soon!
How did you become involved with and interested in open culture and music production? How would you encourage others to get involved?
It all started about 12 years ago. I joined Radio Zero, a student radio station in Lisbon, and they had a very open source-oriented ethos. That’s where I first found out about Creative Commons and, luckily, at that time there were lots of independent music labels in Portugal releasing music under CC. One thing led to another and I ended up doing a show only dedicated to music that was freely (as in beers!) available. It was the precursor of White Market Podcast, my show about CC-licensed music and open culture. What I find really exciting about open music is that there’s so much to discover and everything is accessible. Cultural industries tend to remain heavily closed, reinforcing the idea that culture is a privilege, but CC licenses challenge that and allow you to share your stuff with whoever you want. If you like music, I’d say the best way to start is to dive into larger pools of free music, like Starfrosch, Dogmazic, ccMixter, and Auboutdufil.
What is the role of radio in open source music production? Why is radio art important in the digital age?
Radio is the medium with the widest reach in the world – the International Telecommunication Union estimates that it reaches “95% of virtually every segment of the population” around the the world. As such, it is still a great tool for promoting music regardless of genre, and reaching out to newer audiences. But the connection can grow a lot deeper than that; for non-for-profit stations, open music can also be a valuable resource as it is shared with fewer restrictions than copyrighted music. For instance, stations using CC BY-SA songs can share that share the content they produce under the same license allowing their listeners to engage with their content beyond the broadcast schedule.

How do you “live open” in a closed source world? What open values do you bring to your work in academia and radio?
It can be hard sometimes. Sadly, I don’t think we’re at a stage where you can live fully “open”. We’re all limited by the reality around us: jobs, what friends and family do, etc. I try to keep things as open as possible: creating open processes and using free software is a good start in our daily lives. In academia, I try to follow guidelines regarding open science: using open formats and sharing data whenever possible. Beyond using and sharing only free content, I have tried to set up a collaborative workflow using Github to create content for White Market Podcast. It’s still a work in progress, though.
What are you going to be working on or presenting at the CC Summit?
Darksunn and I will be presenting the recently-formed Open Music Network – a non-profit organization focused on promotion, education and advocacy for the benefits of open music for both professional and personal use. The network links different actors in the open music community – such as platforms, labels, podcasts and radios shows, and even a venue.
What aspect of the CC Summit are you most excited about? What are you most looking forward to?
Just to take part in it is already crazy exciting for me! It’s going to be my first ever CC Summit and it’s a lovely coincidence that it’s taking place right at home. I look forward to welcoming other CC-lovers into Lisbon, as well as learning from their experiences with Creative Commons and in open culture.
A Dark Day for the Web: EU Parliament Approves Damaging Copyright Rules
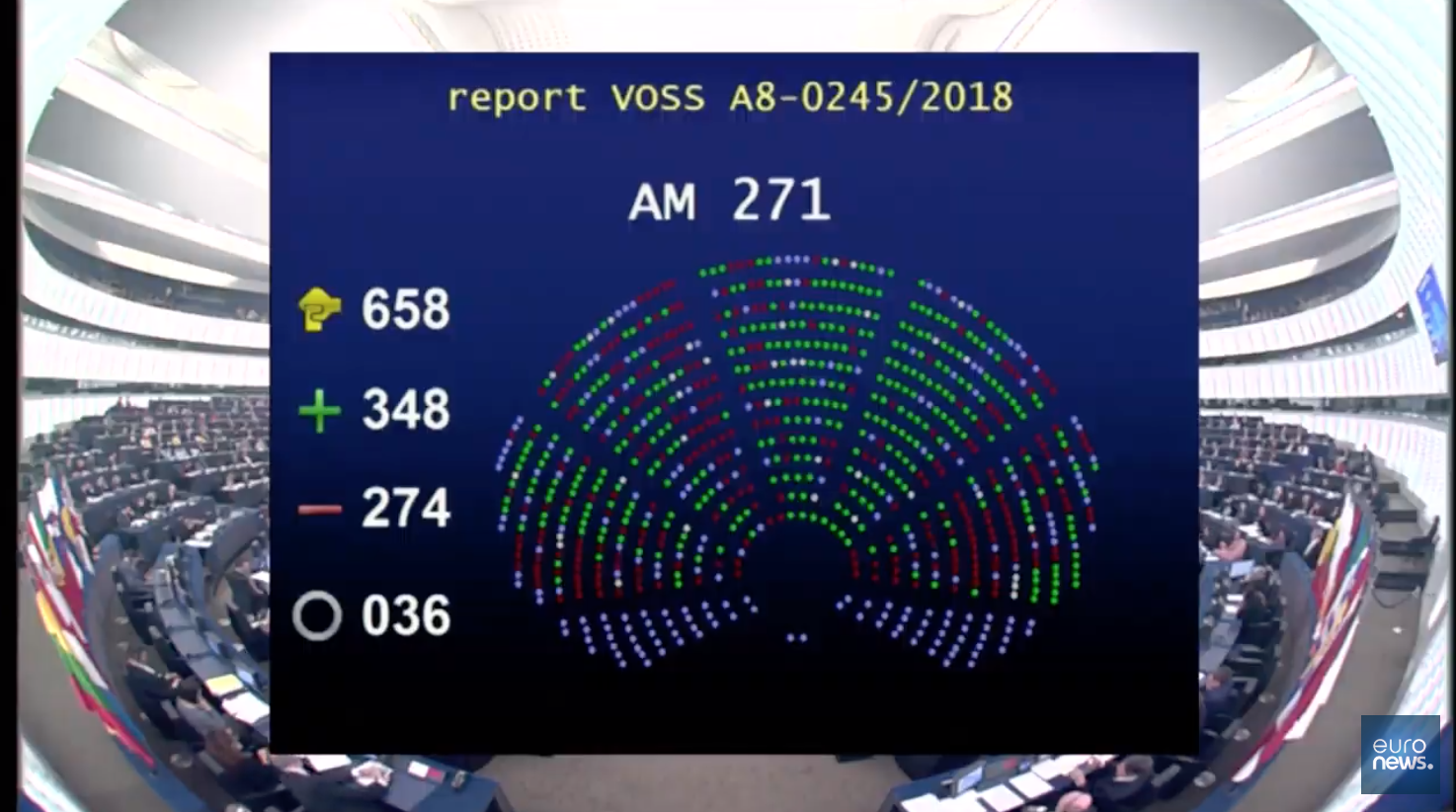
Today in Strasbourg, the European Parliament voted 348-274 (with 36 abstentions) to approve the Directive on Copyright in the Digital Single Market. It retains Article 13, the harmful provision that will require nearly all for-profit web platforms to get a license for every user upload or otherwise install content filters and censor content, lest they be held liable for infringement. Article 11 also passed, which would force news aggregators to pay publishers for sharing snippets of their stories.
There was a potential opportunity to vote on amendments that would have removed the most problematic provisions in the draft directive, particularly Articles 13 and 11, but the preliminary vote even to consider amendments fell short by five votes, thus pushing the Parliament to move ahead and simply approve the entire package.
MEP Julia Reda called the decision “a dark day for internet freedom.” We agree. There was a massive outpouring of protest against the dangers of Article 13 to competition, creativity, and freedom of expression. This included 5+ million petition signatures, a gigantic action of emails and calls to MEPs, 170,000 people demonstrating in the in the streets, large websites and communities going dark, warnings from academics, consumer groups, startups and businesses, internet luminaries, and the UN’s Special Rapporteur on Freedom of Expression. Even so, it was not enough to convince the European legislator to change course on this complex and damaging provision that will turn the web upside down.
Creative Commons CEO Ryan Merkley responded to the vote:
Despite an incredible show of public opposition to the directive, and an abundance of evidence that the proposals will favour large rights holders, damage online communities, slow or even stop innovation, and entrench established big tech players, the European legislature has decided to approve it. Regardless of this outcome, we’ll continue to work with Member States wherever we can to ensure the implementations of this directive minimize the negative impact we anticipate for the commons, and on users who want to share creativity and knowledge online.
We’re disappointed with the decision to push through Article 13 and 11, but the directive is not a total wash. There are some productive changes that will improve the situation of the commons, libraries & cultural heritage, and research sectors. For example, the directive includes a provision to ensure that digital reproductions of public domain works don’t get a separate copyright and will also be in the public domain. It includes text to improve the ability for cultural heritage institutions to preserve works and to make available copyrighted works from their collections that are no longer commercially available. And the directive slightly improves the copyright exception on text and data mining (TDM) by making mandatory an earlier optional provision that would expand the possibilities for those wishing to conduct TDM.
The final outcome of the European copyright directive reflects a disturbing path toward increasing control of the web to benefit only powerful rights holders at the expense of the rights of users and the public interest. It has been — and will continue to be — up to us all to fight for an open internet that sustains new creativity and upholds freedom of expression in the digital environment.
Los europeos deberían decirle al Parlamento que vote NO a los filtros de derechos de autor
 Llegó el momento decisivo para el proyecto de directiva sobre derechos de autor en el mercado único digital de la Unión Europea. Las dramáticas consecuencias negativas que traerían los filtros de carga de contenidos serían desastrosas para la visión que Creative Commons tiene como organización y comunidad global. La inclusión del Artículo 13 hace que la directiva sea imposible de apoyar tal como está.
Llegó el momento decisivo para el proyecto de directiva sobre derechos de autor en el mercado único digital de la Unión Europea. Las dramáticas consecuencias negativas que traerían los filtros de carga de contenidos serían desastrosas para la visión que Creative Commons tiene como organización y comunidad global. La inclusión del Artículo 13 hace que la directiva sea imposible de apoyar tal como está.
El mes pasado, el Parlamento, el Consejo y la Comisión europeos completaron sus negociaciones y llegaron a un acuerdo final sobre el texto de la directiva de derechos de autor. Poco después, los embajadores de los Estados miembros de la UE y la comisión de asuntos jurídicos del Parlamento le dieron luz verde, lo que ahora lleva a una votación final en la sesión plenaria del Parlamento programada para el 26 de marzo.
La semana próxima, los 751 eurodiputados votarán entre adoptar la directiva de derechos de autor o descartarla para volver a empezar de cero.
Los filtros de contenidos modificarán la forma en que funciona la web
Desde una perspectiva de derechos de autor, el Artículo 13 da vuelta el modo en que funciona la web. Obligará a casi todas las plataformas web con fines de lucro que permiten la carga de contenidos generados por los usuarios a que obtengan una licencia para todas las cargas de los usuarios o instalen filtros de derechos de autor y censuren contenidos. Si las plataformas no cumplen, podrían ser legalmente responsables ante demandas por perjuicios masivos por infracción de derechos de autor. El resultado lógico es que esto dañará las plataformas existentes y evitará la creación y el florecimiento de servicios nuevos e innovadores en Europa porque esos nuevos actores no tienen el dinero, la capacidad ni la experiencia para llevar a cabo acuerdos de licenciamiento, o para construir (o contratar) las tecnologías de filtrado necesarias. Por el contrario, las corporaciones ya establecidas se consolidarán aún más y se volverán más dominantes, ya que los servicios como YouTube tienen una ventaja en ambos frentes. No podemos respaldar un ecosistema de derechos de autor que afianzará el amplio poder de mercado de los actores tradicionales y que, al mismo tiempo, creará obstáculos innecesarios para nuevas plataformas y servicios que estimulen la creatividad y el intercambio.
Esta inversión del régimen de responsabilidad, que en los hechos obliga a que sean implementados filtros de contenidos, tiene otra consecuencia desconcertante: los derechos de los usuarios son echados por tierra, porque las tecnologías de filtrado no pueden distinguir cuándo una obra se está subiendo de manera ilícita y cuándo se está utilizando legalmente bajo una excepción a los derechos de autor. Un sistema de este tipo casi seguramente restringirá la libertad de expresión, ya que las plataformas evitarán cualquier riesgo bloqueando el contenido, independientemente de si el uso está protegido por excepciones a los derechos de autor, como por ejemplo las excepciones que habilitan la crítica, la cita y la parodia.
El camino hasta aquí
En los últimos años, Creative Commons ha estado trabajando para respaldar cambios a los derechos de autor en Europa, con el objetivo de favorecer los bienes comunes y el interés público. Hemos hecho esto como parte de la Asociación Communia, en conjunto con organizaciones de la sociedad civil, grupos de investigación, activistas por los derechos de los usuarios y defensores de la web abierta. CC envió comentarios a la consulta inicial de la Comisión Europea, realizó un documento conjunto de análisis y recomendaciones elaborado por nuestra red en Europa, abogó por proteger la investigación científica y brindó recomendaciones de votación sobre muchas disposiciones de la directiva de derechos de autor.
Communia y otras organizaciones no gubernamentales europeas han apoyado cambios positivos en aspectos clave de la reforma que beneficiarían la investigación, la educación y el bien público. En particular, han trabajado para mejorar las excepciones para la minería de datos y de textos, así como las excepciones para la educación, y han propuesto cambios para apoyar el dominio público y para mejorar la capacidad de las instituciones que preservan el patrimonio cultural para poner a disposición los contenidos en línea. Son dignos de celebración los esfuerzos incansables de las organizaciones e individuos que han tomado la iniciativa para defender los bienes comunes y para mejorar varias partes de la directiva con el objetivo de respaldar los derechos de los usuarios. Su investigación detallada, sus aportes de redacción y su activismo han contribuido en gran medida para mejorar muchas partes poco conocidas pero enormemente importantes de la directiva.
Qué puedes hacer ahora
En CC creemos que nuestra visión de acceso universal a la investigación y a la educación, así como de plena participación en la cultura, solo se logrará cuando tengamos políticas de derechos de autor que realmente promuevan la creatividad y protejan los derechos de los usuarios en la era digital. Con el Artículo 13, no es exagerado decir que ocurrirá un cambio fundamental en la forma en que las personas pueden usar Internet y compartir contenidos en línea. A pesar de las pequeñas mejoras en otros aspectos del paquete de reforma de los derechos de autor, en el balance general una directiva que contiene el Artículo 13 hará más daño que beneficio.
Si estás en Europa, ve a https://saveyourinternet.eu/act/ para informarles a tus diputados del Parlamento Europeo que no apoyas una reforma de los derechos de autor que afecta la forma en que creamos y compartimos cultura en la web. Si el Artículo 13 no se puede eliminar, los legisladores deberían rechazar la reforma completa y comenzar de nuevo.
Europeans should tell Parliament to vote NO to copyright filters
It’s the end of the line for the EU’s proposed Directive on Copyright in the Digital Single Market. The dramatic negative effects of upload filters would be disastrous to the vision Creative Commons cares about as an organisation and global community. The continued inclusion of Article 13 makes the directive impossible to support as-is.
Last month the Parliament, Council, and Commission completed their trilogue negotiations and reached a final compromise on the copyright directive text. Soon thereafter the EU Member State Ambassadors and the Parliament’s legal affairs committee gave a green light, now leading to a final vote in the plenary session of the Parliament scheduled for March 26.
Next week all 751 MEPs will get a chance vote on whether to adopt the copyright directive, or send it back to the drawing board.
Upload filters will turn the web upside down
From a copyright perspective, Article 13 turns how the web works on its head. It will require nearly all for-profit web platforms that permit user generated content uploads to either get a license for all user uploads or otherwise install copyright filters and censor content. If the platforms don’t comply, they could become liable for massive copyright infringement damages. The logical outcome is that this will harm existing platforms and prevent the creation and flourishing of new and innovative services in Europe because those new players don’t have the money, pull, or expertise to conclude licensing deals or build (or pay for) the necessary filtering technologies. Instead, the established companies will simply become more entrenched and dominant, as services like YouTube have a headstart on both of these fronts. We cannot support a copyright ecosystem that will simply entrench the extensive market power of incumbent players and, at the same time, create unnecessary roadblocks for new platforms and services that stimulate creativity and sharing.
This reversal of the liability regime that all but ensures upload filters will need to be implemented has another disconcerting consequence: user rights are thrown out the window because filtering technologies can’t possibly know when a work is infringing and when a work is being legally used under an exception to copyright. Such a system will almost surely curtail freedom of expression, as platforms will mitigate any risk by simply blocking content regardless of whether the use is sanctioned under the exceptions to copyright, such as for criticism, quotation, and parody.
The road to here
Over the last several years, Creative Commons has been working to support copyright changes in Europe that champion the commons and the public interest. We’ve done this as part of the Communia Association, civil society organisations, research groups, user rights activists, and open web advocates. CC submitted comments to the initial consultation from the Commission, made a joint analysis and suggestions for improvement with our network in Europe, advocated to protect scientific research, and offered voting recommendations on many provisions within the sweeping copyright directive.
Communia and other NGOs on the ground in Europe have supported positive changes to key aspects of the reform that would benefit research, education, and the public good, particularly working to improve the exceptions for text and data mining and education, as well changes to support the public domain and improve the ability of cultural heritage institutions to make content available online. The tireless efforts of organisations and individuals who stepped up to defend the commons and improve various parts of the directive that supports robust user rights should be celebrated. Their detailed research, writing, and advocacy has done so much to improve many parts not-so-well covered yet incredibly important pieces of the directive.
What you can do now
CC believes that our vision of universal access to research and education and full participation in culture will only be achieved when we all have copyright policies that truly promote creativity and protect users rights in the digital age. With Article 13, it’s no exaggeration to say that it’ll fundamentally change the way people are able to use the internet and share online. Even with some of the minor improvements to other aspects of the copyright reform package, on balance a directive that contains Article 13 will do more harm than good.
If you’re in Europe go to https://saveyourinternet.eu/act/ to tell your MEPs you don’t support a copyright reform that turns how we create and share on the web upside down. If Article 13 can’t be removed, then policymakers should reject the reform outright and begin again.
CC Search: A New Vision, Strategy & Roadmap for 2019
At the Grand Re-Opening of the Public Domain at the Internet Archive, I teased a new product vision for CC Search that gets more specific than our ultimate goal of providing access to all 1.4 billion CC licensed and public domain works on the web. I’m pleased to present that refined vision, which is focused on building a product that promotes not just discovery, but reuse of openly-licensed and public domain works. We want your feedback in making it a reality. What kinds of images do you most need and desire to reuse when creating your own works? Along that vein, what organizational collections would you like to see us prioritizing for inclusion? Where can we make the biggest difference for you and your fellow creators?
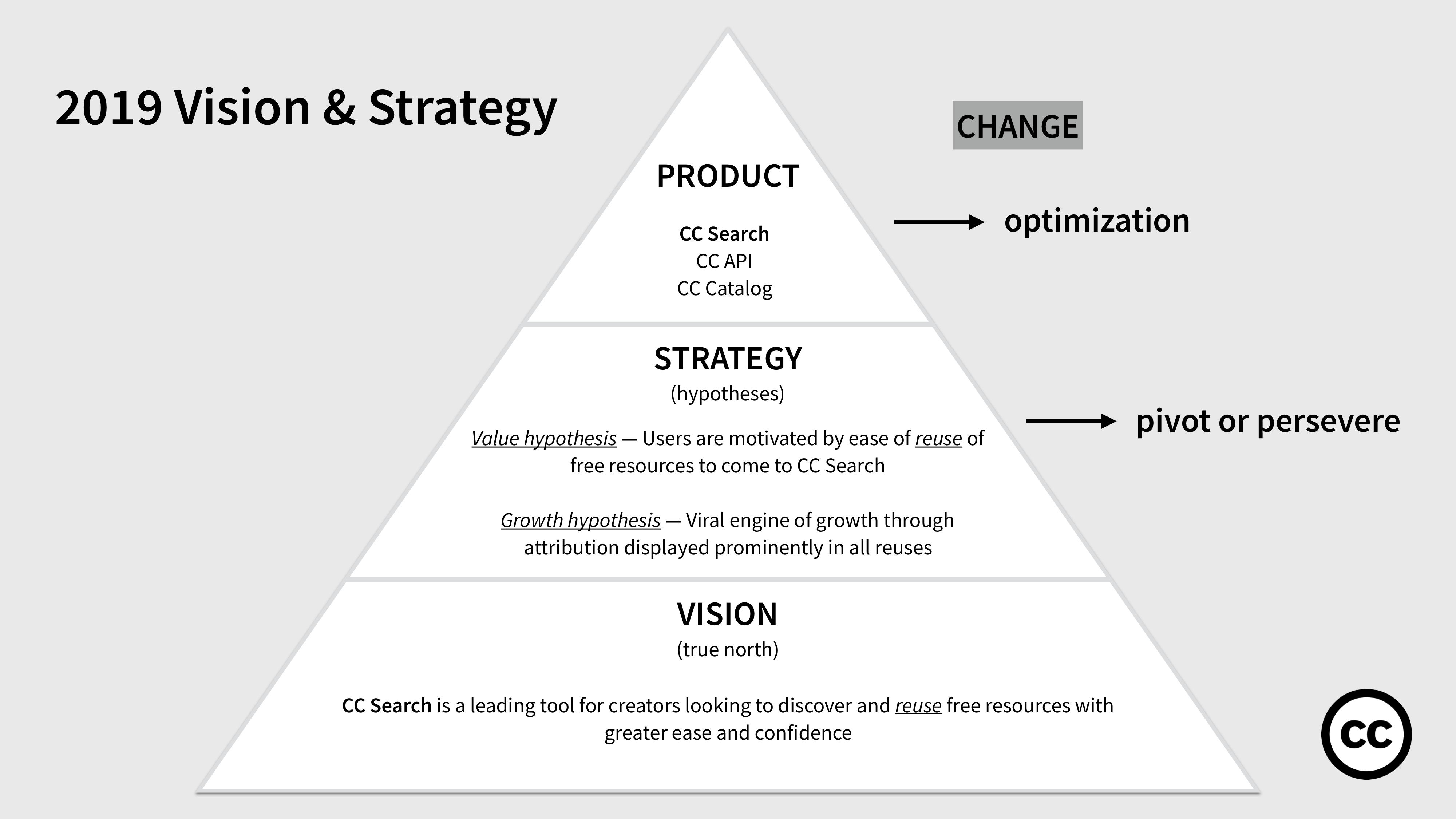
Vision
Our 2019 vision is:
“CC Search is a leading tool for creators looking to discover and reuse free resources with greater ease and confidence.”
The vision centers on reuse — CC will prioritize and build for users who seek to not only discover free resources in the commons, but who seek to reuse these resources with greater ease and confidence, and for whom in particular the rights status of these works may be important. This approach means that CC will shift from its “quantity first” approach (front door to 1.4 billion works) to prioritizing content that is more relevant and engaging to creators.
We made our assumptions based on a combination of user research, whatever quantitative data we could get our hands on (e.g. analytics on previous iterations of search), and pure conjecture (based on anecdotal evidence from our community), or what in the lean start-up world is called a leap of faith.
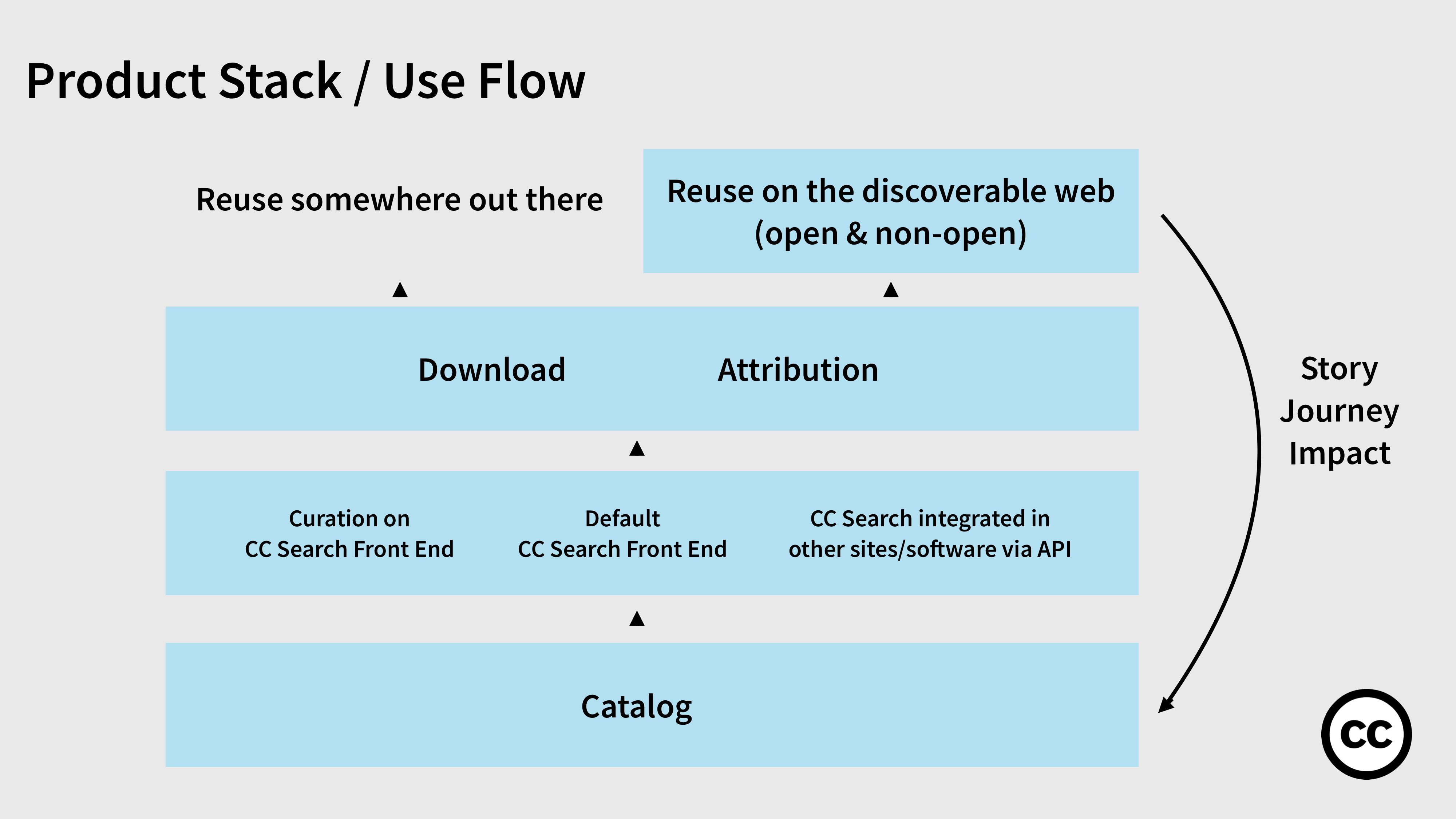
How we expect reuse to happen
The base catalog is the database of all CC works we are continuing to gather and grow. We envision users will be able to access this catalog in three ways:
- Through CC Search — the default front end you see now.
- Through some curation on CC Search — you could imagine different portals for different kinds of users, e.g. educators seeking open textbooks.
- Through CC Search being integrated directly into other sites and software via a CC API, e.g. CC Search in Google Docs.
Once the user accesses the work, the user takes the next step to reuse the work. They download it, which means they make a copy. The user who is also a creator takes a step further; they attribute the author of the work in their new creation, ideally through the automatic and easy ways we provide for them to do this. Both download and attribution are ways a user reuses the work in a way that implicates copyright and thereby the Creative Commons license. And both are potential ways we can learn how that work is used in the wild.
Through learning about how CC works are reused, we will be able to validate our hypotheses and know we are on the right track (or not). We will also be better able to tell the story or journey of the works’ impact, which speaks to a key insight from our user research:
“People like seeing how their work is used, where it goes, and who it touches, but have no easy way to find this out.”
This learning is the hard part of our work, and what we still need to figure out. How do we track and learn about reuse in a way that is effective, but also aligns with our values and respects user privacy?
User research & usability testing
In 2019, we will focus on images and texts, with a stretch goal of including audio files. Accordingly, we will focus any user research and usability testing on groups of people that reuse these works in a meaningful way, specifically, “Creators making new works using existing free content.” A few we will start with are:
- Creators making designs, imagery and art works (commercial or independent)
- Creators illustrating a text or text-based resource (blog, journalistic articles, educational/academic texts or presentations)
- Creators making a video
We’ll also being doing some separate user research to add open texts, which is a different bucket of people than the creators above, because we think (but don’t know) that most people seeking open texts are really seeking access, and not reuse, when it comes to CC Search. For example, we think that community college faculty looking for open textbooks are mainly seeking to access all open textbooks in one place.
As we talk to users, collect user feedback, and conduct usability testing, we may learn differently.
Roadmap
Based on this new 2019 vision and strategy, here are some of our key deliverables for the year.
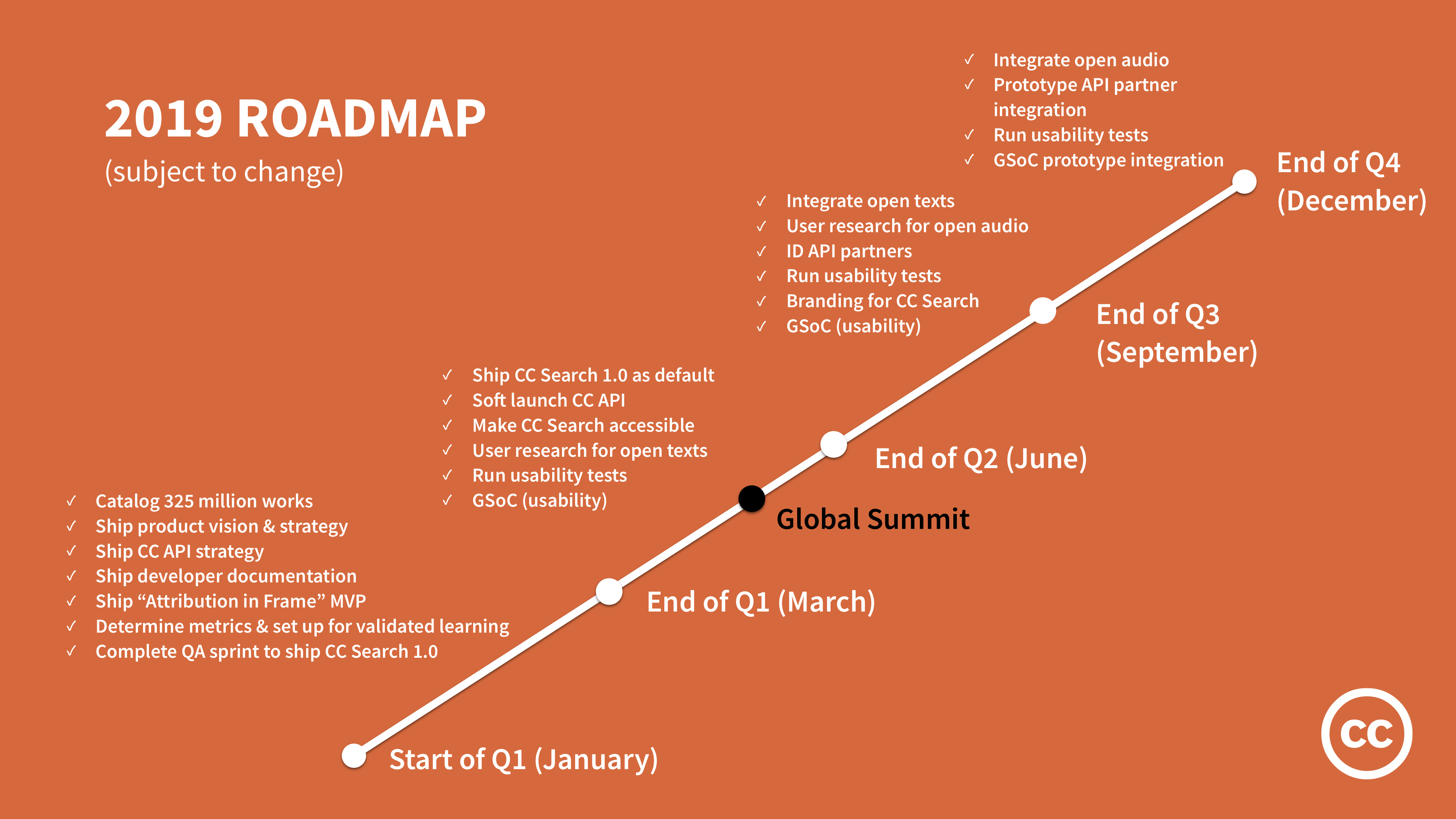
The complete roadmap is available here, which also includes a pipeline of ideas. The pipeline of ideas is the master list of ideas from the community that we will revisit at the end of each quarter to decide what makes it in the roadmap. The roadmap is an evolving document and we welcome your comments and feedback.
The Team

Follow the arrows from upper left: Kriti, Sophine, Alden, Breno, Sarah, Jane
The current CC Search team is led by CC’s Director of Engineering, Kriti Godey, and myself, CC’s Director of Product and Research. The other members are Sophine Clachar (Data Engineer), Alden Page (Back End Engineer), Breno Ferreira (Front End Engineer) and Sarah Pearson (Product Counsel).
Get involved
We are growing a vibrant community of open source developers and users willing to test and provide feedback on CC Search.
If you’re a current or potential user of CC Search, join the #cc-usability channel at the Creative Commons Slack (https://slack-signup.creativecommons.org) where we regularly engage the group for feedback on new features.
If you’re a developer, check out Creative Commons Open Source, a hub for the CC developer community and the #cc-developers channel at the Creative Commons Slack.
Use and Fair Use: Statement on shared images in facial recognition AI
Yesterday, NBC News published a story about IBM’s work on improving diversity in facial recognition technology and the dataset that they gathered to further this work. The dataset includes links to one million photos from Flickr, many or all of which were apparently shared under a Creative Commons license. Some Flickr users were dismayed to learn that IBM had used their photos to train the AI, and had questions about the ethics, privacy implications, and fair use of such a dataset being used for algorithmic training. We are reaching out to IBM to understand their use of the images, and to share the concerns of our community.
CC is dedicated to facilitating greater openness for the common good. In general, we believe that the use of publicly available data on the Internet has led to greater innovation, collaboration, and creativity. But there are also real concerns that data can be used for negative activities or negative outcomes.
While we do not have all the facts regarding the IBM dataset, we are aware that fair use allows all types of content to be used freely, and that all types of content are collected and used every day to train and develop AI. CC licenses were designed to address a specific constraint, which they do very well: unlocking restrictive copyright. But copyright is not a good tool to protect individual privacy, to address research ethics in AI development, or to regulate the use of surveillance tools employed online. Those issues rightly belong in the public policy space, and good solutions will consider both the law and the community norms of CC licenses and content shared online in general.
I hope we will use this moment to build on the important principles and values of sharing, and engage in discussion with those using our content in objectionable ways, and to speak out on and help shape positive outcomes on the important issues of privacy, surveillance, and AI that impact the sharing of works on the web.
We are taking this opportunity to speak to this particular type of reuse – improving artificial intelligence tools designed for facial recognition through the reuse of content found on the web (not just CC-licensed content) – to help clarify how the licenses work in this context. We have published new FAQs here that we will continue to update.
If you have comments or questions, please write CC at info@creativecommons.org. We will also be creating other opportunities to engage in public discussion in the coming weeks and months. We look forward to joining these discussions as we look for ways to resolve ethical public policy issues around data, AI, and machine learning as a community.
Big Flickr Announcement: All CC-licensed images will be protected
I’m happy to share Flickr’s announcement today that all CC-licensed and public domain images on the platform will be protected and exempted from upload limits. This includes images uploaded in the past, as well as those yet to be shared. In effect, this means that CC-licensed images and public domain works will always be free on Flickr for any users to upload and share.
Flickr is one of the most important repositories of openly-licensed content on the web, with over 500M images in their collection, shared by millions of photographers, libraries, archives, and museums around the world. The company was an early adopter of CC licenses, and was bought by Yahoo! and later sold to Verizon. Last year, Flickr was sold again, this time to a family-owned photo service called SmugMug. Many were justifiably concerned about the future of Flickr, an essential component of the digital Commons.
Once the sale of Flickr was announced, CC began working closely with Don and Ben MacAskill of SmugMug, Flicker’s new owners, to protect the works that users have shared. Last November, Flickr posted that they were moving to a new paid service model that would restrict the number of free uploads to 1,000 images. Many, including Creative Commons, were concerned this could cause millions of works in the Commons to be deleted. We continued to work with Flickr, and a week later, they announced that CC-licensed images that had already been shared on the platform would be exempted from upload limits.
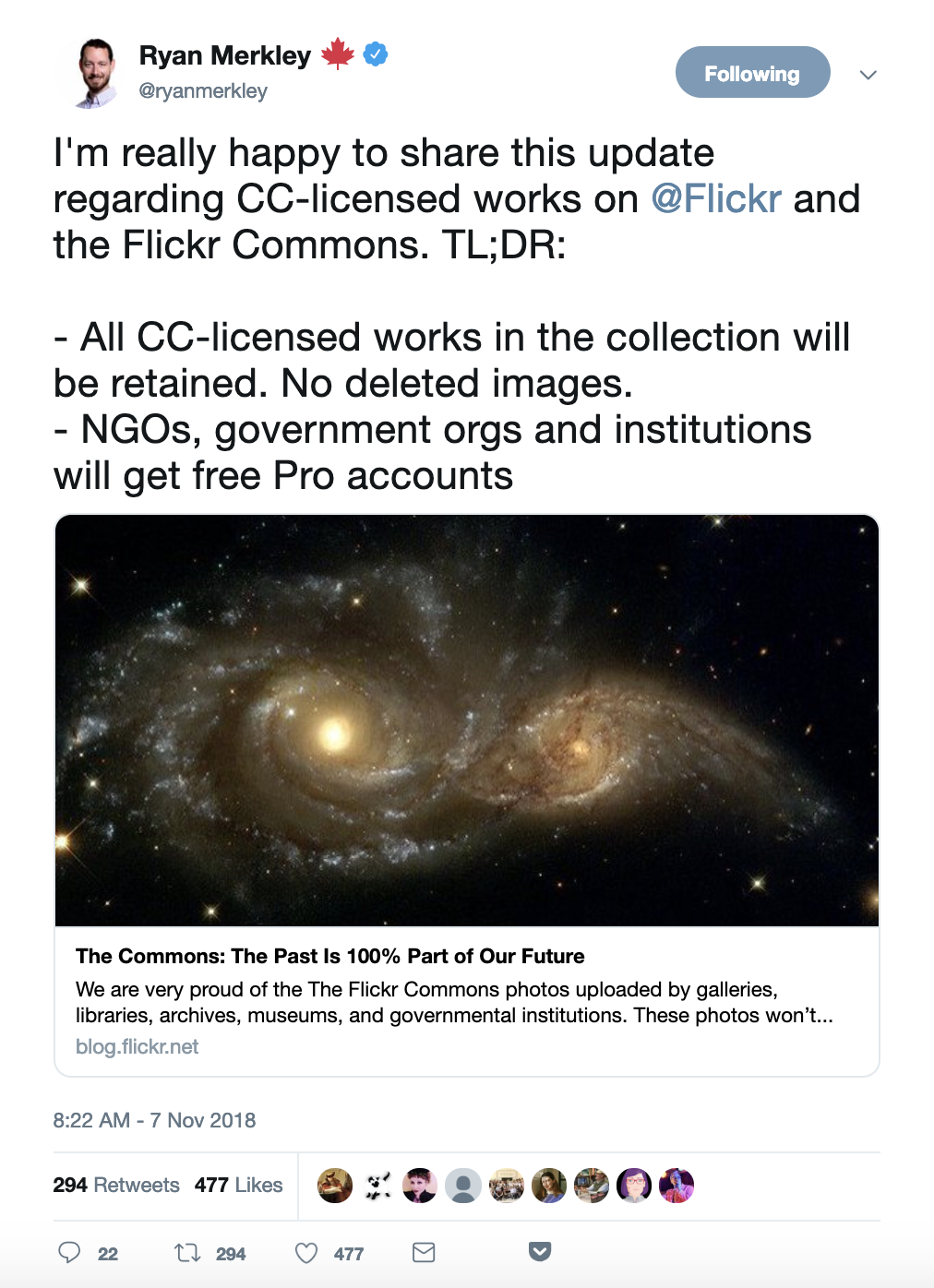
Today’s announcement takes that commitment one step further, and ensures that every CC-licensed or public domain image shared on Flickr is protected for all to use and re-use. It’s a significant commitment. Don and Ben MacAskill and the whole Flickr team have been supportive of CC and Flickr’s responsibility to steward the Commons from day one, and have been open and collaborative with Creative Commons all along.
For users of Flickr (and no doubt also for Flickr staff) it’s been a tumultuous time. Migrating to new business models is difficult, and will undoubtedly anger some users, especially those used to getting things for free. However, we’ve seen how unsustainable and exploitative free models can be, and I’m glad that Flickr hasn’t turned to surveillance capitalism as the business model for its sustainability plan – but that does mean they’ll have to explore other options.
Choosing to allow all CC-licensed and public domain works to be uploaded and shared without restrictions or limits comes at a real financial cost to Flickr, which is paid in part by their Pro users. We believe that it’s a valuable investment in the global community of free culture and open knowledge, and it’s a gift to everyone. We’re grateful for the ongoing investment and enthusiasm from the entire Flickr team, and their commitment to support users who choose to share their works. We will continue to work together to help educate Flickr’s users about their options when sharing works online, and to support the communities contributing to the growth and preservation of a vibrant collection of openly-licensed and public domain works.
CC + Google Summer of Code 2019
 We are proud to announce that Creative Commons has been accepted as a mentor organization for the 2019 Google Summer of Code program.
We are proud to announce that Creative Commons has been accepted as a mentor organization for the 2019 Google Summer of Code program.
Google Summer of Code (GSoC) is a annual global program through which Google awards stipends to university students who write code for free and open-source software projects during their school break. CC has been a mentor organization for GSoC on seven previous occasions, but our last participation was in 2013, so we are glad to be reviving the tradition and hosting students again.
We’ve compiled a list of project ideas for students to choose from when submitting their work proposal. There’s a lot of variety to choose from – adding features to CC Search, reviving older CC products, creating entirely new tools that increase the reach of CC licenses, figuring out ways to better present our legal and technical work, and more. There is definitely room for creativity – the project ideas are defined in broad terms, and students may also choose to submit a proposal for an original idea.
One of the goals of the CC engineering team this year is to build an active developer community around our projects. We’ve been writing free and open-source software for over a decade. Lately, we haven’t done the best job of enabling external developers to contribute to those projects. Hosting Google Summer of Code is our first step to change that for the better, and we’re also actively working on several other improvements to our code and processes, such as:
- Creative Commons Open Source, a hub for the CC developer community.
- Making CC Search’s development more transparent. Our current sprint workload is already public and we’ll be releasing a roadmap soon.
- General cleanup, documentation, and contribution guidelines for our projects.
- A technical blog.
If you want to stay updated on our work, join our brand new developer mailing list, the #creativecommons-dev IRC channel on freenode, or the #cc-developers and #cc-gsoc channels on our Slack community. And if you’re a student (or know a student), please consider submitting a Google Summer of Code proposal! It’s a great way to get an introduction to open-source, build real-world skills, work on interesting technical challenges, and help advance CC’s mission.



